试验镜像:
 小说题材s=image瀑布题材/wate学生题材rmark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG四季题材9nLmNzZG4ubmV0L3FpbmdmZW5neGlhb3Nvbmc=,size_16,color_FFFFFF,t_70″>
小说题材s=image瀑布题材/wate学生题材rmark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG四季题材9nLmNzZG4ubmV0L3FpbmdmZW5neGlhb3Nvbmc=,size_16,color_FFFFFF,t_70″>
下载链接:https://pan.baidu.com/s/15Fc1L3iJEcbXo7SVW9mTfg
提取你的密码:iaom用户名:c205你的密码:一个空格
root你的密码:一个空格
Spark机械去学习库简介
Spark机械去学习库提供了常见机械去学习算法的完成,包罗聚类,分类,回归,协同过滤,维度缩减等。运用 Spark机械去学习库来做机械去学习任务,也可以说是十分的复杂,一般就可要在对原始数据停止处置后,接着直接把挪用响应的ap学生题材i视频题材就可以实现。但是要想选择合适的算法,高效精确地对数据停止剖析,您能够还需要深入了解下算法原理,和响应 SparKM影视题材LlibAPI完成的参数的价值和意义。
需求提到的Spark机械去学习库从 1.2版本当前被分为两个包,辨别是
SparkMLlib历史的比拟长了1.0现在的版本中已经包含了提供更多的算法完成都是基于原始的RDD从去学习角度下去讲,实在比拟很容易上手。假如您曾经无机器学习方面的经历,那么说您就可要熟悉下 MLlibAPI就也可以开端数据剖析任务了想要基于这个包提供的工具使用全面构建完好而且庞大的机械去学习流水线是比拟难题的
SparkMLPipelin从 Spark1.2版本开端,现在曾经从 Alpha阶段结业,成为可用而且较为波动的新的机械去学习库。MLPipelin补偿了原始 MLlib库的缺乏,向用户提供了一个基于 DataFram机械去学习任务流式 API套件,运用 MLPipelinAPI也可以很方便的把数据处理,明显特征转换,正则化,和多个机械去学习算法结合起来,全面构建一个单一完整的机械去学习流水线。很显然,这样的新的形式给我提供更多了更灵活的办法,并且这也更契合机械去学习进程的特征。
从官方发布文档来看,SparkMLPipelin固然是被推荐的机械去学习形式,但是并不会在中短期内替代原始的MLlib库,由于 MLlib曾经包括了丰厚波动的算法完成,而且局部 MLPipelin完成基于 MLlib并且就笔者看来,并不是一切的机械去学习进程都需求被全面构建成一个流水线,有小说题材时候候原始数据花样划一且完整,并且运用单一化的算法就能实现目标,就也没须要把的事庞大化,接纳最复杂且容易理解的形式才是准确的可以选择。
本文基于 Spark1.5向读者展现运用 MLlibAPI停止聚类分析的进程。读者将会发现,运用 MLlibAPI其开发机械去学习使用形式是比拟复杂的置信本文也可以使读者树立起决心并完全掌握根本办法,以便在后续的去学习和任务中事半功倍。
K-mean聚类算法原理
聚类分析是一个无监督学习 UnsupervisLearn进程,普通是用来对数据工具依照其明影视题材显特征属性停止分组,常常被应用在客户会分群,敲诈检测,彩色图像剖析等领域。K-mean所以是最著名而且最经常使用的聚类算法了其基本原理比拟很容易了解,而且聚学生题材类效果良好,有着普遍的运用。
和诸多机械去学习算法一样,K-mean算法也是一个迭代式的算法,其次要具体步骤如下所示:
- 第一步,可以选择 K个点作为初始聚类中心。
- 第二步,盘算其他一切点到聚类中心的间隔,并把每一点划分到离它前段时间的聚类中心所在聚类中去。这里,权衡间隔普通有多个函数也可以可四季题材以选择,最常用的欧几里得距离 Eucl视频题材e=”短片题材” href=”http://www.zibotc.com/”>短片题材ideanDistanc,也叫欧式距离。公式如下所示:
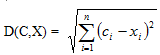
其中包括 C代表中央点,X代表恣意一个非中心点。
- 第三步,再次盘算每一聚类中所有点的均匀值,并将其作为新的聚类中心点。
- 最初,反复 二)视频题材三)步的进程,直至聚类中央不再发作改动,或许算法达到预定的的迭代次数,又或聚类中心的改动小于事后设定的阀值。
实践使用中,K-mean算法有两个不得已面临而且克制的成绩。
- 聚类个数 K可以选择。K可以选择是一个比拟有大学问和讲究的具体步骤,会在后文特意描绘怎样运用 Spark提供更多的工具使用可以选择 K
- 初始聚类中心点的可以选择。可以选择差别的聚类中央能够招致聚类结果的差别。
SparkMLlibK瀑布题材-mean算法的完成在初始聚类点的可以选择上,自创了一个叫 K-means||类 K-means++完成。K-means++算法在初始点可以选择上遵照一个基本原则:初始聚类中央点相互之间的间隔所以尽可能多的远。根本具体步骤如下所示:
K-均值算法试图将一系列样本联系成K个不同的类簇(其中包括K模子的输出参数)其形式化的目的函数称为类簇内的方差和(withinclustersumofsquarerrorWCSSK-均值聚类的作文题材目的最小化一切类簇中的方差之和。规范的K-均值算法初始化K个类中心(为每一类簇中所有样本的均匀向量)前面的进程不时反复迭代上面两个步骤。
1将样本分到WCSS最小的类簇中。由于方差之和为欧拉距离的平方,以是最初等价于将每一样本平均分配到欧拉距离最近的类中心。
2依据第一步类平均分配状况再次盘算每一类簇的类中心。K-均值迭代算法完毕基本条件为达到最大的迭代次数或许收敛。收敛之意着第一步类平均分配后也没改动,因而WCSS值也没有改变。
数据集地址:
试验进程
启动后Hadoop集群
start-all.sh

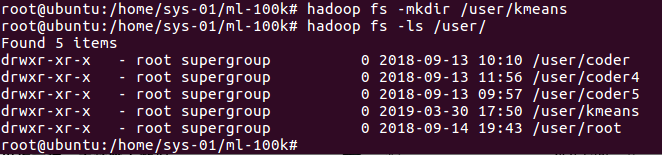
hdf中创立文件夹
hadoopfs–mkdir/user/kmeans
hadoopfs–ls/user/
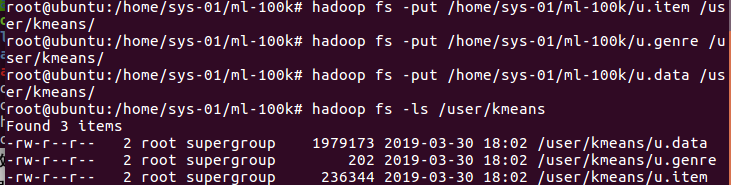
将文件上传到hdf文件零碎中
hadoopfs-put/home/sys-01/ml-100k/u.item/user/kmeans/
hadoopfs-put/home/sys-01/ml-100k/u.genr/user/kmeans/
hadoopfs-put/home/sys-01/ml-100k/u.data/user/kmeans/
数据明显特征提取
启动后spark-shell

读取三个文件
vmovi=sc.textFil”hdfs://localhost:9000/user/kmeans/u.item”
vgenr=sc.textFil”hdfs://localhost:9000/user/kmeans/u.genre”
vrawData=sc.textFil”hdfs://localhost:9000/user/kmeans/u.data”

提取影戏的题材题目,小说题材并从u.genr文件中提取题材的直接映射之间的关系
vgenreMap=genres.filt!_.isEmpti.mapline=>line.split”|”.maparrai=>arrai1,arrai0.collectA sMap
print短片题材lngenreMap
vtitlesA ndGenr=movies.map_.split”|”.map{arrai=>
valgenr=array.toSeq.slic5,array.s
valgenresA ssign=genres.zipWithIndex.filt{caseg,idx=>
g==”1″
}.map{caseg,idx=>
genreMapidx.toStr
}
arrai0.toInt,arrai1,genresA ssign
}
printlntitlesA ndGenres.first

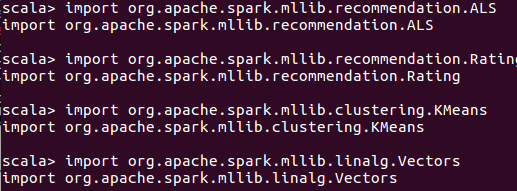
导入过度依赖包
importorg.apache.spark.mllib.recommendation.A LS
importorg.apache.spark.mllib.recommendation.Rating
importorg.apache.spark.mllib.clustering.KMeans
importorg.apache.spark.mllib.linalg.Vectors
运转ALS模子天生影戏和用户因素
vrawRat=rawData.map_.split”t”.take3
vrate=rawRatings.map{caseArraiuser,movie,rate=>Rateuser.toInt,movie.toInt,rating.toDoubl}
ratings.cache
valsModel=ALS.trainratings,50,10,0.1

提取因子向量
vmovieFactor=alsModel.productFeatures.map{caseid,factor=>id,Vectors.densfactor}
vmovieVector=movieFactors.map_._2
vuserFactor=alsModel.userFeatures.map{caseid,factor=>id,Vectors.densfactor}
vuserVector=userFactors.map_._2

性训练聚类模型
MLlib中训练K-均值的办法和其他模子相似,只需把包括性训练数据的RDD传入KMeans工具的train办法只需。留意,由于聚类不需要标签,以是不必LabeledPoint实例,而是运用明显特征向量接口,即RDDVector数组即可。MLlibK-均值提供更多了随机和K-means||两种初始化方法,后者是默许初始化。由于两种方法都是随机可以选择,以是每次模子性训练的后果都不一样。K-均值一般不能够收敛到全局最优解,以是实践使用中需求屡次性训练并选择最优的模子。MLlib提供更多了完成4屡次模子性训练的办法。经由造成的损失函数的评价,将性能最好的一次性训练选定为最终的模子。
代码完成中,先需求引入须要的模块,设置模子参数:KnumClusters最大迭代次数(numIteration和训练次数(numRuns接着,对电影的系数向量运行K-均值算法。最初,用户有关要素的明显特征向量上训练K-均值模子
影戏因子向量上运行k均值模子
vnumClust=5
vnumIter=10
vnumRun=3
vmovieClusterModel=KMeans.trainmovieVectors,numClusters,numIterations,numRun

性训练用户模子
vuserClusterModel=KMeans.trainuserVectors,numClusters,numIterations,numRun
运用聚类模子停止展望
K-均值最小化的目的函数是样本到瀑布题材其类中心的欧拉距离之和,便可以将最接近类中心界说为最小的欧拉距离
界说欧氏距离函数
importbreeze.linalg._
importbreeze.numerics.pow
defcomputeDistv1:DenseVector[Double],v2:DenseVector[Double]:Doubl=powv1-v2,2.sum

应用下面的函数对每一影戏盘算其明显特征向量与所属类簇中心向量的间隔:
vtitlesWithFactor=titlesA ndGenres.joinmovieFactor
vmoviesA ssign=titlesWithFactors.map{caseid,title,genr,vector=>
valpred=movieClusterModel.predictvector
vclusterCentr=movieClusterModel.clusterCentpred
//求两坐标的间隔
valdist=computeDistDenseVectorclusterCentre.toA rrai,DenseVectorvector.toA rrai
id,title,genres.mkStr””,pred,dist
}
vclusterA ssign=moviesA ssigned.groupBi{caseid,title,genres,cluster,dist=>cluster}.collectA sMap
//pred为预测出的该点所属的聚点
//vector也可以了解为该点的坐标向量
//clusterCentre为该pred聚点的坐标向量

穷举每一类簇并输入间隔类中心最近的前20部电影
fork,v<-clusterA ssignments.toSeq.sortBi_._1{
printlns”Cluster$k:”
valm=v.toSeq.sortBi_._5
printlnm.take20.map{case_,title,genres,_,d=>title,genres,d}.mkString”n”
println”=====n”
}
Clust0包括了许多20世纪40年月、50年月和60年月的老电影,和一些近代的戏剧

Clust1次要是一些恐怖电影

Clust2有非常一部分是悲剧和戏剧电影

Clust3和戏剧相关

Clust4次要是举措片、惊悚片和言情片

正如你看到并不能够分明看出每一类簇所表示的其他内容。但是也有证据标明聚类进程会提取影戏之间的属性或许类似之处,这不是纯粹基于影戏称号和题材很容易看出来的比方外语片的类簇和传统电影的类簇,等等)假如我有更多元数据,比方导演、演员等,便有能够从每一类簇中找到更多特征定义的细节
评价聚类模型的功能
与回归、分类和引荐引擎等模型类似,聚类模子也有许多直接评价办法用于剖析模子功能,和评价模子样本的拟合度。聚类的评价一般分为两部分:外部评价和外部评估。外部评价表现评价进程运用性训练模子时使用的性训练数据,内部评价则运用性训练数据除了的数据。外部直接评价目标WCSS之前提过的K-元件的目的函数),使类簇内部的样本间隔尽可能多靠近,差别类簇的样本绝对较远。
MLlib提供更多的函数computeCost也可以利便地盘算出给定输入数据RDD[Vector]WCSS上面我运用这个办法盘算影戏和用户性训练数据的功能
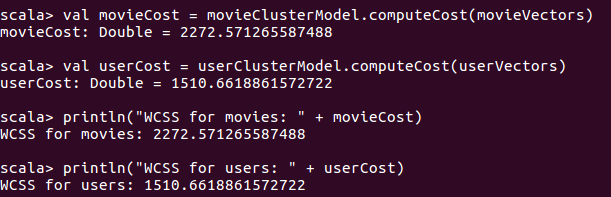
盘算影戏和用户集群的本钱(作文题材WCSS
vmovieCost=movieClusterModel.computeCostmovieVector
vuserCost=userClusterModel.computeCostuserVector
println”WCSSformovies:”+movieCost
println”WCSSforusers:”+userCost
聚类模子参数调优
差别于以往的模子,K-均值模子只要一个可以调的参数,就是K即类中心数目。
影戏集群的穿插验证结果
vtrainTestSplitMovi=movieVectors.randomSplitArrai0.6,0.4,123
vtrainMovi=trainTestSplitMovi0
vtestMovi=trainTestSplitMovi1
vcostsMovi=Seq2,3,4,5,10,20.map{k=>k,KMeans.traintrainMovies,numIterations,k,numRun.computeCosttestMovi}
println”Moviclustercross-validation:”
costsMovies.foreach{casek,cost=>printlnf”WCSSforK=$kid$cost%2.2f”}

用户集群的穿插验证结果
vtrainTestSplitUs=userVectors.randomSplitArrai0.6,0.4,123
vtrainUser=trainTestSplitUs0
vtestUser=trainTestSplitUs1
vcostsUser=Seq2,3,4,5,10,20.map{k=>k,KMeans.traintrainUsers,numIterations,k,numRun.computeCosttestUser}
println”Userclustercross-validation:”
costsUsers.foreach{casek,cost=>printlnf”WCSSforK=$kid$cost%2.2f”}

从后果也可以看出,随之类中央数量添加,WCSS值会出现下降,接着又开始增大。此外一个现象,K-均值在穿插验证结果的状况,WCSS随之K增大继续减小,但是达到某个值后,持续下降的速度忽然会变得很平缓。此时的K一般为最优的K值(这称为拐点)
原文链接:https://blog.csdn.net/qingfengxiaosong/article/details/91428057?ops_request_misc=%257B%2522request%255Fid%2522%253A %2522166856496116782414955790%2522%252C%2522scm%2522%253A %252220140713.130102334.pc%255Fblog.%2522%257D&request_id=166856496116782414955790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-23-91428057-null-null.nonecase&utm_term=%E9%A 2%98%E6%9D%90
未经允许不得转载:题材网 » sparkmllib库 停止影戏聚类分析(Scala言语)
影视题材.四季题材png”>最大。

